Web Scraping Job Postings
CONCEPT
CONCEPT
In this Project my two main objectives were : 1] Determine the industry factors that are most important in predicting the salary amounts for these data. 2] Determine the factors that distinguish job categories and titles from each other. For example, can required skills accurately predict job title? Need to scrape and prepare the data.
DATA
Firstly, I have scraped the data from the site using beautifulsoup4 to get job listings for the titles,
Data+Scientist','Data+Analyst' and 'Data+Engineer'.we ended up having a data frame of shape 3210 , 5 .
The 5 columns are Title,Company,Salary,State and Description.As most of the data do not have salary values,they needed to be dropped because the
problem statement is based on salary.After loading into the DataFrame ,i strarted analysing the data by doing some EDA and Feature engineering.
i ended up with clean data of size 285 , 5
In my exploratory data analysis phase,i found out that most of the jobs are from NSW when coampred to all other states.
The highest salary in the dataset is for the titile "Head of Data Science and the pay is 300K PA and is from state NSW.
The median salary is 95K PA.Most of the job postings were of title data analyst followed by data science and data engineer.
Feature engineering title column and extracted senior ,mid, and junior levels. Additionally added skills column by extacting
skills from the description.
PROCESS
In order to analyze the data and generate insights out of it, i followed the a process that looked at the data using the following visualizations:
- Job postings across all states
- Exploratory Data Analysis using Tableau
- Boxplots to see outliers
- confusion matrix
- Scatter Plot
- Bipartite Graph
- ROC
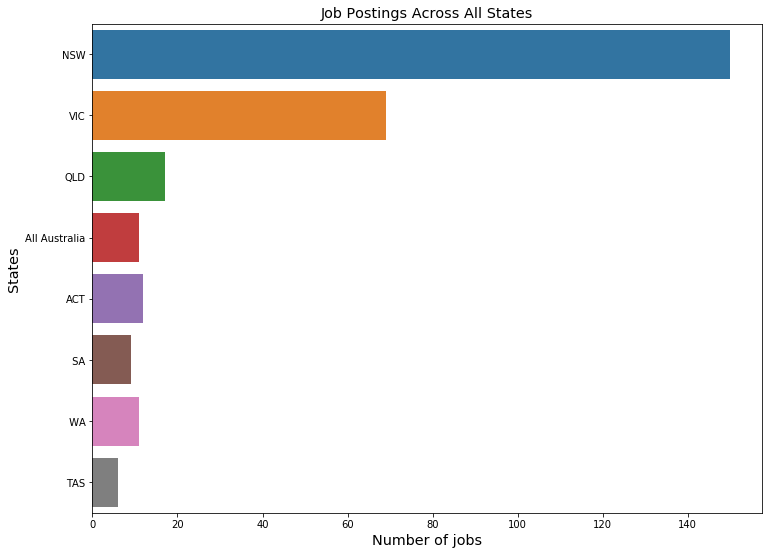
Job Postings Across All States
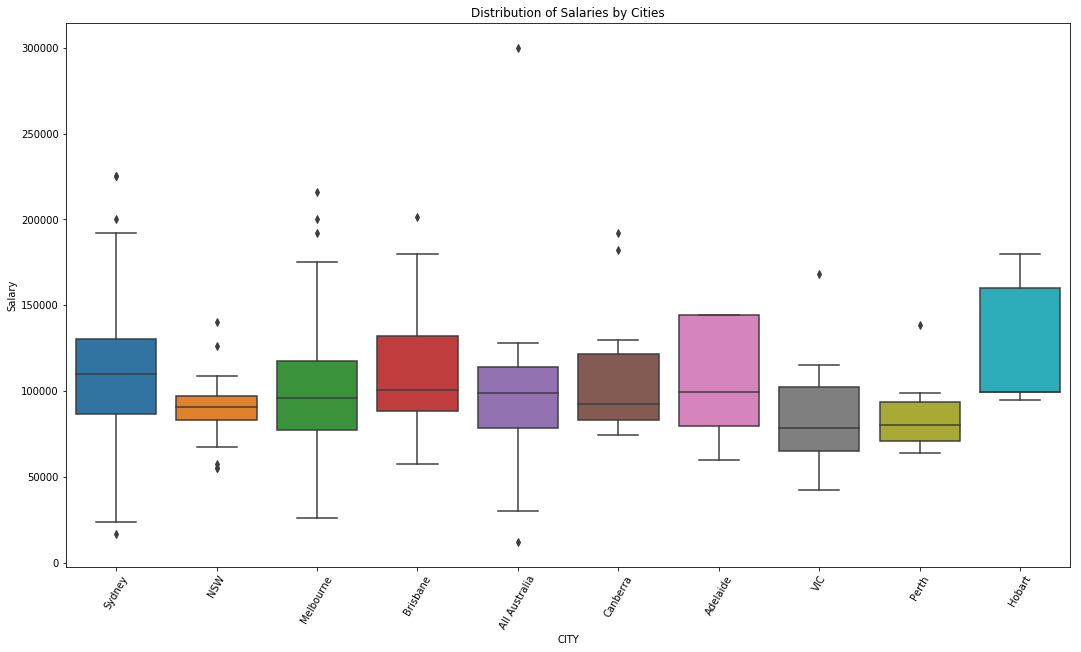
Distribution of salaries
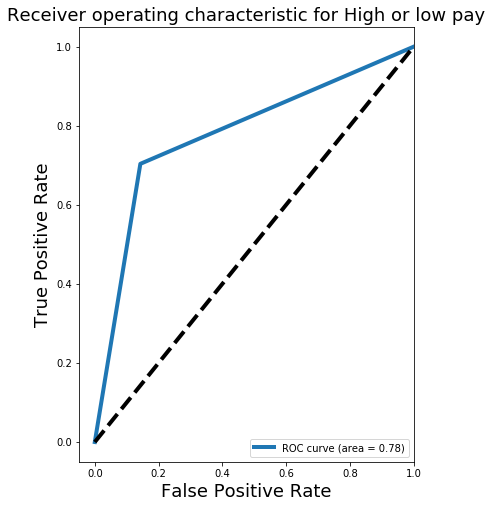
ROC Curve