Automated Enterprise Data Ingestion and Reporting Pipeline
CONCEPT
CONCEPT
This project focuses on designing and implementing a fully automated,
scalable data ingestion pipeline that reliably processes data from
multiple upstream systems and delivers trusted, analytics‑ready datasets.
The primary objectives were:
1] Automate ingestion from multiple source systems with minimal manual effort.
2] Enforce robust data quality checks and proactive issue notifications.
3] Provide end‑to‑end visibility of ingestion status to engineering,
product, and business teams.
DATA
Data is sourced from multiple internal and external providers in varying
formats and delivery schedules. Incoming datasets are securely landed
on a centralised SFTP server and standardised prior to ingestion.
The solution supports incremental and full loads while maintaining
historical traceability and auditability across all ingestion cycles.
APPROACH
The pipeline is orchestrated end‑to‑end using Azure Data Factory (ADF),
coordinating data movement, validation, processing, and reporting workflows.
Automated data quality checks are applied early in the pipeline to validate
schema consistency, completeness, and business rules. If issues are detected,
automated email notifications are triggered to source data providers with
detailed error context.
Upon successful validation, data is processed and stored using a medallion
architecture (Bronze, Silver, and Gold layers) to ensure a clear separation
between raw, curated, and analytics‑ready data.
TECHNOLOGIES USED
The platform leverages a modern cloud‑native data stack:
-
Orchestration and Scheduling
- Azure Data Factory (ADF)
- Power Automate
-
Data Processing and Storage
- Azure Databricks
- Snowflake Data Warehouse
- Secure SFTP
-
Analytics and Reporting
- Power BI (Datasets, Dataflows, Reports)
- Ingestion Status and Audit Dashboards
OUTCOME
The solution significantly improved data reliability, reduced ingestion failures, and eliminated manual monitoring. Real‑time Power BI dashboards provide full transparency into pipeline health, while automated notifications keep engineering and product teams informed of ingestion status and downstream impacts.
View Architecture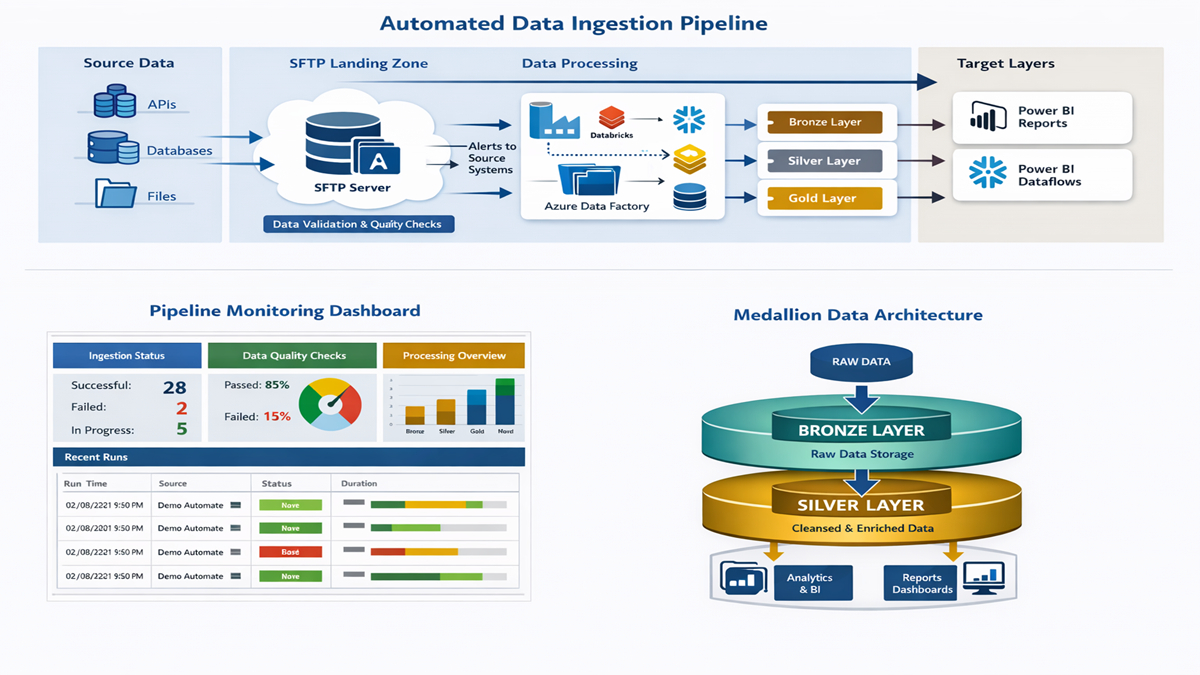
End‑to‑End Architecture